RHEL7 Failover Cluster
In this tutorial we will see how to create a cluster between two Red Hat Enterprise Linux (RHEL) 7 virtual machines. I installed them on ESXi platform, with 2 vPCU and 2 GB of RAM each, but this is a detail. Three IP addresses are required, one for each RHEL server and one as a virtual IP for the cluster. Virtual machines need to communicate with each other.
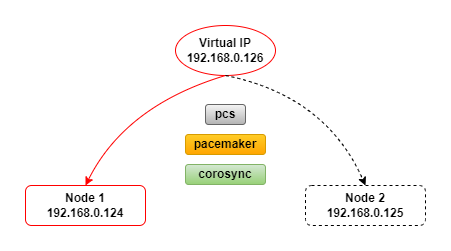
In my sample architecture I have:
- Server 1
- Name: vm-rh74-svr1
- IP: 192.168.0.124
- Server 2
- Name: vm-rh74-svr2
- IP: 192.168.0.125
- Cluster VIP
- IP: 192.168.0.126
Installation
We install the RHEL 7.x operating system with minimal configuration on both servers and configure them with a static IP address. To avoid communication problems between the nodes we disable SELinux and disable the firewall on both.
Once installed, we add an entry for each node in the /etc/hosts file for name resolution, on both virtual machines.
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.0.124 vm-rh74-svr1 vm-rh74-svr1.localdomain
192.168.0.125 vm-rh74-svr2 vm-rh74-svr2.localdomain
If you don’t have an active RHEL Subscription, let’s set up the local repository for yum, one for the standard RHEL packages, and one for the HighAvailability package group.
# echo "[rhel-dvd]" > /etc/yum.repos.d/rhel-dvd.repo
# echo "name=rhel-dvd" >> /etc/yum.repos.d/rhel-dvd.repo
# echo "baseurl=file:///mnt/cdrom" >> /etc/yum.repos.d/rhel-dvd.repo
# echo "enabled=1" >> /etc/yum.repos.d/rhel-dvd.repo
# echo "gpgcheck=0" >> /etc/yum.repos.d/rhel-dvd.repo
# echo "[rhel-ha-dvd]" > /etc/yum.repos.d/rhel-ha-dvd.repo
# echo "name=rhel-ha-dvd" >> /etc/yum.repos.d/rhel-ha-dvd.repo
# echo "baseurl=file:///mnt/cdrom/addons/HighAvailability" >> /etc/yum.repos.d/rhel-ha-dvd.repo
# echo "enabled=1" >> /etc/yum.repos.d/rhel-ha-dvd.repo
# echo "gpgcheck=0" >> /etc/yum.repos.d/rhel-ha-dvd.repo
So, we install pcs pacemaker fence-agents-all, on both virtual machines .
# yum --disablerepo=\* --enablerepo=rhel-dvd,rhel-ha-dvd install pcs pacemaker fence-agents-all
In order to use pcs for cluster configuration and allow communication between nodes, a password must be set on each node for the user ID hacluster, which is the pcs administration account. It is recommended to use the same password for the hacluster user on each node.
# passwd hacluster
Changing password for user hacluster.
New password:
Retype new password:
Now we can start pscd, corosync and pacemaker on both nodes.
# systemctl start pcsd.service
# systemctl enable pcsd.service
# systemctl daemon-reload
# systemctl start corosync.service
# systemctl enable corosync.service
# systemctl daemon-reload
# systemctl start pacemaker.service
# systemctl enable pacemaker.service
# systemctl daemon-reload
And at this point we proceed with the authentication of the psc hacluster user for each node.
# pcs cluster auth vm-rh74-svr1 vm-rh74-svr2
Username: hacluster
Password:
vm-rh74-svr1: Authorized
vm-rh74-svr2: Authorized
Cluster configuration
Once pcs is installed, you need to run the following command from vm-rh74-svr1 to create the cluster vm-rh74-cluster. This will propagate the cluster configuration files to both nodes.
# pcs cluster setup --start --name vm-rh74-cluster vm-rh74-svr1 vm-rh74-svr2
Then let’s check the status of the cluster.
# pcs cluster status
Cluster Status:
Stack: corosync
Current DC: vm-rh74-svr2 (version 1.1.16-12.el7-94ff4df) - partition with quorum
Last updated: Mon Jun 18 17:06:32 2018
Last change: Mon Jun 18 17:06:07 2018 by hacluster via crmd on vm-rh74-svr2
2 nodes configured
0 resources configured
PCSD Status:
vm-rh74-svr1: Online
vm-rh74-svr2: Online
We add the VirtualIP resource.
# pcs resource create VirtualIP IPaddr2 ip=192.168.0.126 cidr_netmask=24 --group mygroup
Then let’s check the cluster status again.
# pcs status
Cluster name: vm-rh74-cluster
WARNING: no stonith devices and stonith-enabled is not false
Stack: corosync
Current DC: vm-rh74-svr2 (version 1.1.16-12.el7-94ff4df) - partition with quorum
Last updated: Mon Jun 18 17:23:59 2018
Last change: Mon Jun 18 17:19:19 2018 by root via cibadmin on vm-rh74-svr1
2 nodes configured
1 resource configured
Online: [ vm-rh74-svr1 vm-rh74-svr2 ]
Full list of resources:
Resource Group: mygroup
VirtualIP (ocf::heartbeat:IPaddr2): Stopped
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
The message above indicates that the VirtualIP resource has stopped, which means that there are errors with the cluster. To check for errors in the configuration and if there are still any we can use the following command.
# crm_verify -L -V
error: unpack_resources: Resource start-up disabled since no STONITH resources have been defined
error: unpack_resources: Either configure some or disable STONITH with the stonith-enabled option
error: unpack_resources: NOTE: Clusters with shared data need STONITH to ensure data integrity
Errors found during check: config not valid
From the above message there is still an error related to STONITH (Shoot The Other Node In The Head), which is a mechanism used to ensure that you are not in the situation where both nodes think they are active and own the virtual IP, also called a split brain situation. Since we have a basic 2 node cluster, we will simply disable the stonith option.
# pcs property set stonith-enabled=false
We can also configure quorum settings. Quorum describes the minimum number of nodes in the cluster that must be active, for the cluster be considered available, and by default, quorum is considered too low if the total number of nodes is less than twice the number of active nodes. This means that for a 2 node cluster both nodes must be available to have an active cluster. In our case this wouldn’t make sense, because we’re experimenting with a two-node cluster, so we disable quorum checking.
# pcs property set no-quorum-policy=ignore
To avoid split brain situations, we can configure a location constraint for cluster resources, in order to prefer one node. An INFINITY value for the score indicates that the resource will prefer that node if that node is available, but does not prevent the resource from running on another node if the preferred node is unavailable.
# pcs constraint location mygroup prefers vm-rh74-svr1 INFINITY
# pcs constraint --full
Location Constraints:
Resource: mygroup
Enabled on: vm-rh74-svr1 (score:INFINITY) (id:location-mygroup-vm-rh74-svr1-INFINITY)
Enabled on: INFINITY (score:INFINITY) (id:location-mygroup-INFINITY-INFINITY)
Ordering Constraints:
Colocation Constraints:
Ticket Constraints:
Now check the status with both nodes active.
# pcs status
Cluster name: vm-rh74-cluster
Stack: corosync
Current DC: vm-rh74-svr2 (version 1.1.16-12.el7-94ff4df) - partition with quorum
Last updated: Tue Jun 19 11:11:05 2018
Last change: Tue Jun 19 10:45:09 2018 by root via cibadmin on vm-rh74-svr1
2 nodes configured
1 resource configured
Online: [ vm-rh74-svr1 vm-rh74-svr2 ]
Full list of resources:
Resource Group: mygroup
VirtualIP (ocf::heartbeat:IPaddr2): Started vm-rh74-svr1
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
From the previous message the cluster is online and the VirtualIP resource is assigned to node vm-rh74-svr1.
Now let’s shut down the vm-rh74-svr1 node and check the status.
# pcs status
Cluster name: vm-rh74-cluster
Stack: corosync
Current DC: vm-rh74-svr2 (version 1.1.16-12.el7-94ff4df) - partition with quorum
Last updated: Tue Jun 19 11:18:59 2018
Last change: Tue Jun 19 10:45:09 2018 by root via cibadmin on vm-rh74-svr1
2 nodes configured
1 resource configured
Online: [ vm-rh74-svr2 ]
OFFLINE: [ vm-rh74-svr1 ]
Full list of resources:
Resource Group: mygroup
VirtualIP (ocf::heartbeat:IPaddr2): Started vm-rh74-svr2
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
As you can see the cluster is still online and the VirtualIP resource is now started on the second node vm-rh74-svr2.
We then restart the vm-rh74-svr1 node and, after booting, check the status again.
# pcs status
Cluster name: vm-rh74-cluster
Stack: corosync
Current DC: vm-rh74-svr2 (version 1.1.16-12.el7-94ff4df) - partition with quorum
Last updated: Tue Jun 19 11:20:55 2018
Last change: Tue Jun 19 10:45:09 2018 by root via cibadmin on vm-rh74-svr1
2 nodes configured
1 resource configured
Online: [ vm-rh74-svr1 vm-rh74-svr2 ]
Full list of resources:
Resource Group: mygroup
VirtualIP (ocf::heartbeat:IPaddr2): Started vm-rh74-svr1
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
As we can see the cluster is online and the VirtualIP resource is now started on the first node vm-rh74-svr1. This happened because we configured a location constraint for cluster resources to prefer node vm-rh74-svr1.
Cluster migration tests can also be triggered with the following command:
# pcs cluster stop vm-rh74-svr1
vm-rh74-svr1: Stopping Cluster (pacemaker)...
vm-rh74-svr1: Stopping Cluster (corosync)...
# pcs cluster start vm-rh74-svr1
vm-rh74-svr1: Starting Cluster...